![]()

![]()
![]()
Googleのランキング決定の仕組みは複雑さを増しており、その全てを把握することは非常に困難です。その中でも、Web上の”評判”や、それに関わる品質の算出方法が単純なロジックで作られているとは考えづらいです。
今回の記事は、Googleの品質評価のアルゴリズムに関する非常に難解なトピックを扱っておりますが、得られる考えは特別なものではないと考えています。結論としては、「適切だと思われることはすべて行うべき」ということになりますが、記事の最後には、その重要性を再確認できるものと思われます。
※今回の記事は、15,000文字弱と非常に長いものとなっておりますので、ぜひまとまった時間のある時に読んでいただければと思います。
検索結果上のトップの座を維持したいのであれば、Webサイトのユーザービリティとコンテンツの品質の算出方法について学ぶ必要があるだろう。
私は、10年以上前から、Googleが自然検索のランキングに品質スコアを使用する可能性を唱えてきた。また、GoogleがWebサイトの品質を定量化するための複数の方法と、定量化のために不可欠となる特定の要素についても意見を述べてきた。
ここ最近のコアアルゴリズムの更新やメディック・アップデート、また、Googleによる品質評価ガイドラインの公開は、そのビジネスの評判がSEOにおける鍵となることを示唆している。Googleの自然検索のランキングにおける品質の定量化の仕組みに興味があれば、この記事を読み進めてほしい。
Googleが品質スコアを自然検索に用いる可能性を私が初めて示唆したのは2007年のことだった(外部記事:Google Quality Scores for Natural Search Optimization)。
また、次のようなページの重要性についても意見を述べてきた。
Googleのアルゴリズムがどの方向に進化していくのかは、こうした要素から読み取れるのだ。
Googleの「品質評価者のためのガイドライン(Quality Evaluators Guidelines)」、または、「品質評価ガイドライン(QRG:Quality Rating Guidelines)」に書かれていることは、上記の私の主張と近しい内容となっている。
目次
品質評価ガイドラインに記載されている品質に関する要素は、Googleの検索順位により大きな影響を与えているようになっている。
このようなことを言うと、「まいったなー。彼は品質評価ガイドラインについて見当違いの発言をしているよ」と思われるかもしれない。
他方で書かれているとおり、また、(過去の流出も含め)品質評価ガイドラインが公開されて以来、Googleは評価者による点数はランキングに直接の影響を与えない、と明言しているからである。特に、ジェニファー・スレッグ氏は、ダニー・サリバン氏から「人間の評価者による評価は、アルゴリズム用の機械学習に使用されていない」という証言を得ている(外部記事:Google Does Not Use Quality Raters for Machine Learning Algos)。
彼はTwitterでの返信(ツイートへのリンク)にて、「我々はそのように用いていない」と発言しているのだ。ダニー・サリバン氏はさらに、「評価者のデータはレストランが用いるフィードバック用のメッセージカードのようなものだ。レストランはそれによって、彼らの”レシピ”がうまくいっているかどうかを確認している」と続けている(ツイートへのリンク)。
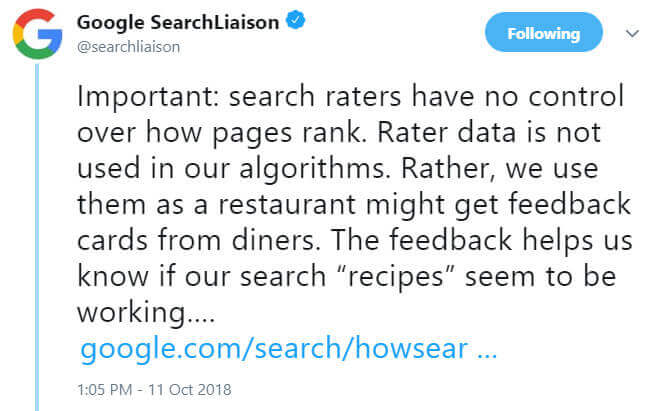
重要事項:評価者は検索結果のランキングのコントロールはできない。評価者によるデータは我々のアルゴリズムに用いられていない。我々は評価者によるデータを、レストランが提供したディナーのフィードバックを受け取るような形で用いている。そのフィードバックは、我々の検索”レシピ”がうまく機能しているかを知る手助けとなるのだ。
多くの人がガイドラインで言及されている特定の事柄をランキングシグナルのように扱っている。特に、Googleが”E-A-T”と呼ぶ、専門性(Expertise)、権威性(Authority)、信頼性(Trust)については顕著だ。
例えば、マリー・ハイネス氏は、品質評価ガイドラインで言及されている事柄がランキング要素に影響している可能性を主張している。例えば、BBB(*1)のランキングや著者の評判といった要素だ。
もちろん、この主張に反対している者もいる。また、Googleのジョン・ミュラー氏は、Googleは著者の評判を調査しておらず(YouTube)、BBBのランキングのような格付けも使用していない(YouTube)と述べている。
*1 Better Business Bureau:アメリカの商事改善協会
同時に、Google社員はWebマスターに対し、「ただ品質のみに注力すべし」とアドバイスを送っている。そして、可能な限り高品質なコンテンツを作成するために、品質評価ガイドラインを読むことも勧めている。これは、昨年10月のコアアルゴリズムの更新が行われたさい、ダニー・サリバン氏が言及したことでもある。
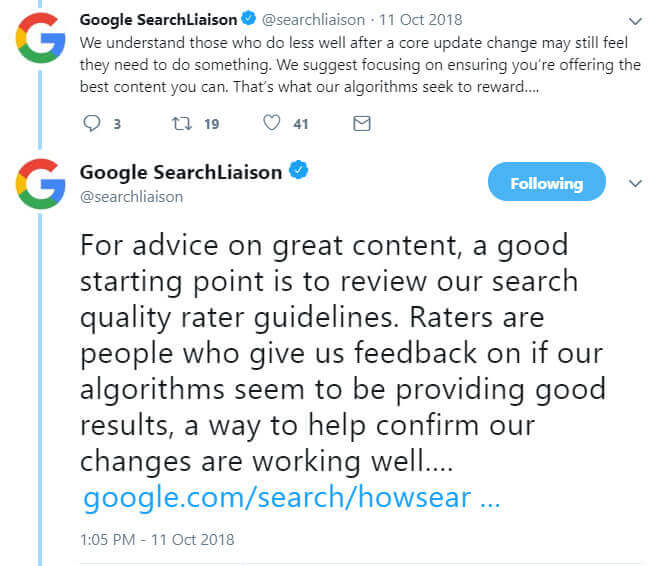
優れたコンテンツ作成のためのアドバイスとして、Googleの品質評価ガイドラインを読むことを勧める。評価者は、Googleのアルゴリズムが適切な検索結果を提供しているかについてのフィードバックを与えてくれる人々であり、我々が行った変更がうまく行っているかを確認する手助けとなっている。
そして、Google検索・Googleアシスタント・GoogleニュースのVPであるベン・ゴメス氏も昨年のインタビューで下記のように述べている(外部記事:We sat in on an internal Google meeting where they talked about changing the search algorithm — here’s what we learned)。
品質評価ガイドラインを「我々がアルゴリズムを向かわせたい場所」と捉えることができる。品質評価ガイドラインにはアルゴリズムがどのようにしてランキングを作成しているかについて書かれているわけではない。しかし、アルゴリズムが行うべき根本的な内容について書かれている。
論点をうまくズラされているようにも感じる。GoogleはWebサイトの品質をアルゴリズムによってどの程度正確に判断できているのか。もちろん、これにはある程度主観的とも思える、専門性・権威性・信頼性・評判も含まれている。Googleのアルゴリズムはこうした概念を定量的な基準に落とし込まなければならない。また、そうした基準は測定可能であり、競合しているサイトやページ間の比較も可能である必要がある。
過去のアルゴリズムのいくつかは、このプロセスを指し示していたと思う。そして、人々がGoogleに尋ねた質問の内容、Google社員が様々な形で返答した内容、人々がその返答を解釈した内容に齟齬があったとも考えている。多くの推測が、考えの浅い、理論的な要素に注力していたようだ。その中には、Google社員が直接否定していた要素も含まれている。
もし、Googleが人間の評価者にサイトのE-A-Tを算出するように依頼し、しかし、検索結果のランキングにはそれらを組み込まないのであれば、アルゴリズムは何を使用しているのだろうか?BBBの格付け、ユーザーレビュー、信用のあるリンクの分析、などを使用しているというのは非常に限定的な意見だろう。
同様に、Googleはリンクの信頼性の分析(Producing a ranking for pages using distances in a web-link graph)やクエリの分析(Site quality score)のみに品質の算出方法を求めているわけではないだろう。Googleは、明らかに、単純なリンクやクエリの分析以上の要素を考慮にいれているはずだ。もちろん、リンクやクエリの分析の要素もある程度は含まれているはずではあるが。
Googleが過去に取得した特許の内容を把握することが、彼らが実際に品質評価に使用している要素を推測する手助けとなるだろう。実際の要素とかなり近しいはずであるし、それらは機械学習の技術を用いている。”Webサイトの品質シグナルの生成(Website Quality Signal Generation)”がそれにあたる。
また、この特許が取得された2013年に、ビル・スラウスキ氏によってそのあらすじがまとめられている(外部記事:How Google May Rank Web Sites Based on Quality Ratings)。Webサイトの品質を測るための方法、また、分析アルゴリズムがそうした評価とWebサイトのシグナルを関連付ける方法について説明されている。定量的なシグナルと人間によって算出された評価との関連性を自動的に特定する仕組みだ。そして、特徴的なシグナルからモデルを生成するのである。
こうした各モデルは、まだ評価付されていないWebサイトとの比較に用いられ、品質評価をそうしたWebサイトに付与するために使用される。これについての説明(以下に記載)は非常に魅力的なものである。
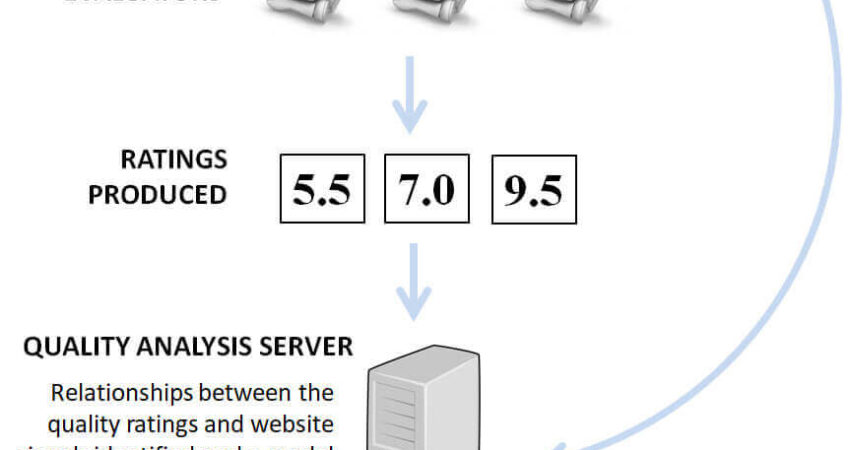
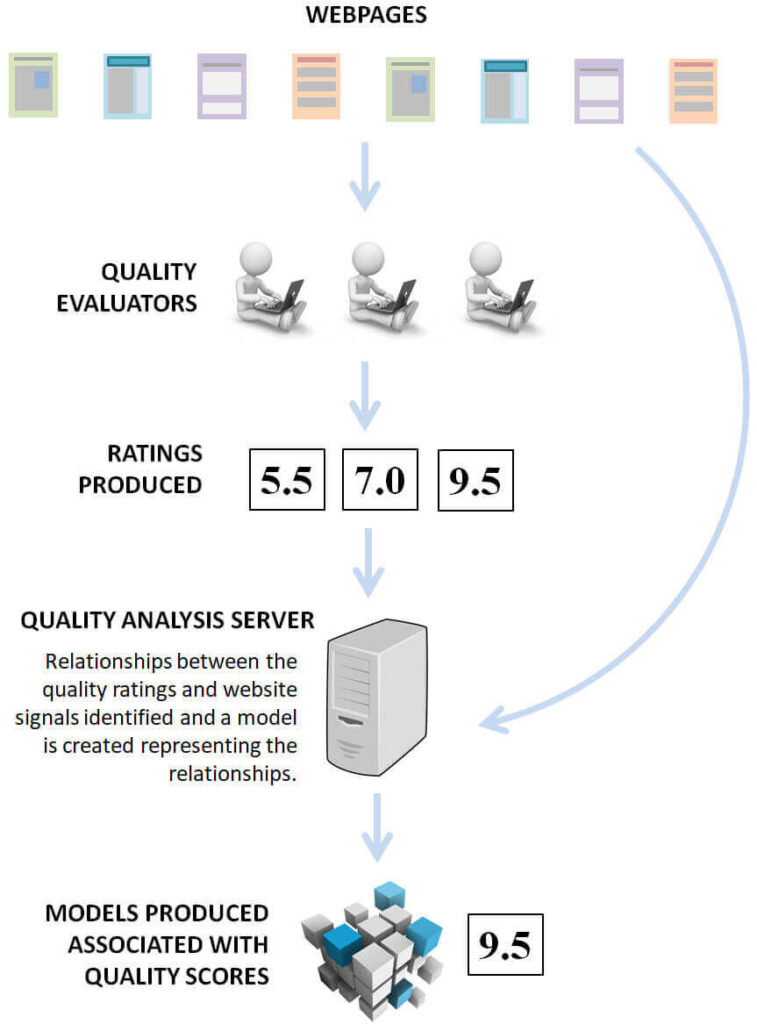
評価者(人間)はWebサイトを閲覧するためにインターネットに接続できる環境にあり、各Webサイトの評価付けを行う。評価者はWebサイトの評価を、評価入力装置(rating input device)を通して、品質分析サーバー(quality analysis server)に送信することができる。
品質分析サーバーは、評価入力装置から、Webサイトの評価を受け取り、それをシグナル・ストア(signal store)に格納する。Webサイトの評価はURLと、また、評価付けされたWebサイトと近しい他のWebサイトのシグナルと関連付けられる。
品質分析サーバーは、Webサイトの品質評価とWebサイトのシグナルの関連性を特定し、その関連性を表すモデルを作成する。
さらに、品質分析サーバーは評価付けされていないWebサイト(例えば、品質評価を示すシグナルが欠落しているサイト)を発見するためにシグナル・ストアを検索する。品質分析サーバーは、評価付けされていないwebサイトが品質評価に関連するシグナルを有しているかどうかを判断し、評価付されていないサイトへモデルを適用する。そのモデルのアプリケーションが算出された品質評価となる。
品質分析サーバーは、モデルによる算出された品質評価を、該当のWebサイトに適用する。算出された品質評価は、他のアプリケーションによって使用される目的で、シグナル・ストアに格納される、追加されたWebサイトのシグナルとなる。
検索エンジンは、シグナル・ストアに格納された、Webサイトのシグナルを使用することができる。検索結果におけるふるい分けと並び順を決定するために、格納されたそのWebサイトの品質評価を元に、使用するのだ。
例えば、一定のしきい値を下回る品質評価を持つサイトをふるい分けするために使用される。また、検索デバイスによって返されたWebサイトは、格納された品質評価したがって順位づけされている。
格納された品質評価が高いWebサイトは、品質評価が低いWebサイトよりも検索結果に表示される優先度が高くなっている。
特許の内容には品質評価に用いられているであろう要素の例が、いくつか記載されている。
文法の正確さ、Webページで記載されているテキストのスペル、不適切な素材の有無、空白や不完全なページの有無、その他Webサイトの品質に影響を与える要素、などが品質評価の要素として使用される。
ここに記載されている内容が、まさに品質評価ガイドラインに記載されている内容であることに気がつくだろう。
しかし、特許の内容に非常に説得力が有るという理由は、これだけではない。Webサイトの評価を算出するための方法とランキングを決定づけるために使用される品質スコアの生成方法について、非常にロジカルなフレームワークで説明されているからなのである。比較的小規模なサンプルからモデルが生成され、そのモデルが他の複数の似たWebサイトに対し横断的に使用できる、という方法について説明されているのだ。
あなたが品質スコアを作りたいと思うページがあると仮定しよう。例えば、健康について書かれている情報記事、つまりは、品質評価ガイドラインでYMYL(Your Monery or Your Life*2)と説明されているページだ。Googleは上記で言及した、測定可能なシグナルを使用することができる。
例えば、コンテンツの量、ページのレイアウト、広告の数、ページ内の広告の表示位置(アバブ・ザ・フォールドやインタースティシャル。つまり、広告がメインコンテンツに対し紛らわしかったり煩わしかったりしないか)、サイトについてのレビュー、サイトと異なる場合のコンテンツ作成者のレビューや被リンク、ページからの発リンク(コンテンツ作成者の特定や情報のソースの参照)、サイトやページの被リンク(ページランク)、主要なキーワードの検索結果におけるクリック率、ページのコンテンツ・検索結果のスニペット・メタディスクリプションとページ上部のヘッドラインやタイトルの一致性、などのサイトの信頼性を指し示す要素だ。
*2 金融や医療など、誤った情報を与えてしまうことで、ユーザーの人生に大きな影響を与えかねない領域
複数の同様のページのテストの後、Googleは品質シグナルの組み合わせのモデル(または、パターン)を作成し、スコア値を算出する。そして、健康系のトピックを扱った記事ページが、ある一定の基準を満たしたページランクのようなシグナル、同様のページのコンテンツのレイアウトや量、内部リンクに由来するページランク、クリック率、ユーザーレビューを保持していたとする。
この場合、Googleは算出された品質スコアを、人間による評価を一切しないで、割り当てることができるのだ。Googleはこのようなモデルを、複数の異なるタイプのページに対し、作成していると考えられる。
この一連の流れにGoogleが機械学習の技術を組み込んでいると思われる理由は、データ内の品質スコアの関連性と紐付いているからである。このデータとは、異なる重み付けを手動で設定する単純なトグルのようなものではない。特定のシグナルに対し重み付けを行う煩わしい作業ではないのだ(例えば、特定の品質スコアのレベルを持つ健康系のトピックは最低でもXのページランクを持ち、最低でもこのくらいのリンク数を持つ、といったものではない)。
機械学習の技術を用いることで、評価システムはより複雑な関連性を特定できるのだ(例えば、ページランクがNからNN、CTRがXからXX、レイアウトが特定のタイプ、の場合は特定の品質スコアを付与するといった具合だ)。
特許の内容がその可能性を指し示している。
モデルはWebサイトのシグナルとサポートベクター回帰を実装した機械学習のサブシステムを用いるWebサイトの品質評価に由来するものである。
本質的に、これは機械学習の階層を生み出す。モデルは共通の階層の全てのページの特定、品質スコアの算出、そして、同質、または同様のスコアを同質のクラスのページへの適用などに使用される。
Googleがデータを該当のページから直接インプットするかどうか、また、それらの品質評価者の評価が機械学習システムに組み込まれるかどうかは大きな問題ではないと考えている。Googleは様々な種類のページの”モデル”を使用し、品質評価がどのようにそれらを算出したかを確認し、手動でその重み付けを調整できる。
しかし、Googleが保持し、好きに使用できる莫大な火力を考慮に入れると、私は全く意味を成さないと考える。事実、エリック・エンジ氏やマーク・トラファガン氏(外部記事:Why Google Uses Machine Learning in Search – Here’s Why #176)のように、多くのSEO分析者がGoogleは機械学習の技術をコンテンツのランキングに用いていると考えているし、Googleもクエリの解釈のみに使用しているわけではないとアナウンス(外部記事:FAQ: All about the Google RankBrain algorithm)している。
コアアルゴリズムの変更により順位が下落したサイトに対しGoogleが提供する曖昧なアドバイスの説明にもなる。サポートベクター、または、ニューラルネットワークは非常に包括的なスコアを伴うのだ。そのため、特定の現象に対しての原因を考えるさい、なにか特定のシグナル、もしくは複数のシグナルを指摘することは、不可能であるといえるのだ。その原因は非常に複雑なモデルに内包されており、とても抽象的なものであるからだ。
算出されたモデルが検索結果のランキングに適用された後、その検索結果に対し、Googleは品質評価者による評価付けを再度行う。これを繰り返し行うことで、検索結果を調整し、時間をかけてより良いものにしていくのだ。
Googleが品質スコアに組み込むと考えられるシグナルは非常に複雑である。下記に記載してみよう。
または、その進化系のシグナル。リンクの品質や信頼性も含むかもしれない。
Googleの品質評価ガイドラインはレビュー数に一定のしきい値を設けていることを示唆している。そのため、あるビジネスやWebサイトの総レビュー数が比較的少なかった場合、非常に曖昧で状態を正確に表していないため、Googleはそれらを無視するという選択をするかもしれない。
Googleは感情分析の調査を長いこと行っており、それを実施するための特許も取得している(Domain-specific sentiment classification)。過去にはローカルリストに表示もしていた(外部記事:Google Highlights Review Sentiments On Local Place Pages)。現在、ランキングに使用しているかどうかについてははっきりとしていない(外部記事:Google Suggests They Use Off-Site Sentiment Analysis For Ranking)。
しかし、実質的にはGoogleは感情を使用することを明示している(外部記事:Google Suggests They Use Off-Site Sentiment Analysis For Ranking)。GoogleがWebサイトの評判をランキングアルゴリズムに組み込んでいるのであれば、感情分析無しで、どうやってランキングの調整を行っているのだろうか? 品質評価の算出はいくぶん不明瞭なものであるが、感情分析は、その分析と仕様の対象として、比較的明確であるだろう。
人々はあなたのプロダクトについてSNSやEメールで言及しているだろうか? ソーシャルメディアの”バズ”は人気度を測る指標であり、そこでの感情も同様に品質の測定となりうる。
クリック率がランキング要素であるかどうかについての議論は長いことされてきている。
しかし、広告のクオリティスコアに使用されているのであれば、自然検索のランキングにも使用されているのではないだろうか? ウォール・ストリート・ジャーナルによって事故的に発表(外部記事:FTC Google Probe Recommendation)されてしまった2012年の情報公開法(freedom-of-information-act)にて、Googleの旧サーチクオリティ・チーフであるウディ・マンバー氏が下記のように言及したのだ。
ランキングはクリックデータに影響される。例えば、特定のクエリで80%のユーザーが2位に表示されているWebサイトをクリックし、1位に表示されているWebサイトをクリックする人が10%しかいなかった場合、人々が求めているのは2位に表示されているWebサイトであるといえる。こうした状況が発見された場合、我々はその順位を入れ替える可能性がある。
CTRがランキングに影響することを説明する調査もあれば、影響はないとする調査もある。もし、CTRが品質スコアの一部でしかない場合、CTRは直接のランキング要素ではなく、これが調査によって異なる結果が出る説明となるかもしれない。
全ページのどれくらいの領域が広告によって占められているだろうか? Googleは、良いしきい値と悪いしきい値を計算しているかもしれない。どのくらいの数の広告があるか、メインコンテンツを過度に侵食していないか、インタースティシャルや閉じることのできないオーバーレイであるかどうか、スコロールしても広告が追ってくるだろうか。このような広告の煩わしさの程度が算出されている可能性がある。
理想を言えば、Webサイトは”我々について(About)のページ”や”お問い合わせ(Contact Us)ページ”を持つべきである。我々について(About)のページはどのような会社であるかを説明し、欲を言えば、写真とともに優秀な会社のメンバーも掲載したい。
お問い合わせ(Contact Us)のページは可能な限りの量の問い合わせ先の情報を掲載する。番地を含む住所、電話番号、お問い合わせフォームなどだ。会社メンバーのページからソーシャルメディアやLinkedinのページへのリンク(逆もまた然り)も設置したい。Webサイトに訪れたものの、その裏側には誰がいるかがわからない状態ほど、悪いものはない。
HTTPSは必須条件だ。
しかし、単純にHTTPSかどうかである以上のことをGoogleは見ていると、私は考えている。なぜなら、暗号化やその設定は全てが同一ではないからだ。
Googleクロームは不備のあるHTTPSに対し、警告を表示するようになっている。ECサイトや金融情報を提供しているサイトは、利用規約、個人情報の扱い、カスタマーサービスへの問い合わせ先などの情報を記載するべきだ。また、ヘルプセクションやリターンポリシーも重要だろう。かつて、私はトラストバッジ(Trust Badges*3)を目立たせるようにしていた。
おそらく、Googleはトラストバッジ自体をWebサイトの品質評価には使用していないだろうが、ユーザーにとって信頼性を高めることになるし、セールスを強化するという効果も期待できるだろう。
*3 データの収集を適格に行っていることを証明する印
言うまでも無いが、かつてページスピードは広告のクオリティスコアの要素であった。そして、今日の自然検索結果においては、品質評価の一種として用いられている。
品質評価ガイドラインでは、特定のタイプの記事や情報サイトは、必要に応じて定期的に見直され、更新されることに言及している。医療、法律、金融、税についてのアドバイスなどが該当する。
もし、自身のサイトがこのようなタイプの情報を掲載しているのであれば、定期的に内容を見直し、変更が加えられた場合には、該当の記事の目立つところに、”更新日”を記載することを勧める。同様に、Webサイトを横断してフッターに記載されているCopyrightの更新漏れも、品質の測定に関わっているかもしれない。更新がされていないと、Webサイト自体が更新されておらず、最新情報が記載されていないと判断されてしまうかもしれない。
その他の要素としては、欠陥のあるウィジットやアプリの使用、画像切れやリンク切れのページ、最近の情報と掲載しつつも明らかに古いコンテンツへのリンクの掲載、などが挙げられる。
Googleは、クロールしたさいに出くわした空白のページ、十分な内容がないコンテンツの割合を確認することができる。Webサイトの大部分でエラーが発生している場合、更新を怠っており、メンテナンスも不十分であるという事実を示すことになる
価値のないコンテンツが放置されているサイトでは、非常に優れた記事が1記事あったとしても、ユーザーは他のページをクリックし、不満足な状態のコンテンツに出くわす可能性が高まってしまう。
これについて多くを言及する必要はないだろう。このようなタイプのコンテンツは、非常に低い品質評価を受ける可能性が急激に高まってしまう。自身の品質スコアを急激に落としたい場合は、このようなコンテンツを追加するといいだろう。
注意したいことは、Webサイトは他のサーバーからひっぱってこられた、このようなコンテンツを表示する広告にも責任を負う必要があるということだ。自身のサイト内に何が表示されているか、細かいところまで配慮する必要があるだろう。
品質スコアの仕組みにおける興味深い観点として、品質スコアはリンク先のページやドメインの品質スコアと関連している可能性が挙げられる。
品質スコアはリンクグラフ全体の総数から繰り返し計算され、これはページランクアルゴリズムの算出方法に近しいものとなっている。これにより、品質スコアの値の重み付けがされ、高品質なコンテンツであることの確証が得られ、品質の低いコンテンツが検索結果の奥底に表示されるようになるのだ。
バリー・シュワルツ氏がメディック・アップデートで影響を受けたサイトの調査を公表している。私も簡単な調査を行ったが、メディック・アップデートで影響を受けたサイトは、品質スコアに影響を与えるであろう要素や、品質評価ガイドラインで言及されている要素が欠落していることに気がついた。
*4 2018年8月1日にGoogleが実施したアップデートの俗称。医療・健康系のサイトが大きな影響を受けたとされている。
我々についてのページがない。無限スクロールが採用されており、プライバシーポリシーや規約についてのページが読み込まれていない可能性がある。お問い合わせページが記載されているのは別のドメイン。記事の執筆者の評判を見てみると、必ずしも医療系の専門家ではない。非常に大きな広告やサイドバーのモジュールはとても煩わしい。
リダイレクトされ、スタッフ紹介はアニメーション、テキストがなく、電話番号や住所の記載もない。コンタクトフォームは、人であることを認証するためのボタンをクリックした後でのみ、表示される。
カスタマーサービスへの問い合わせの電話番号が見つけにくく、サブドメインへリダイレクトされる。
我々についてのページがトップページへリダイレクトされる。電話番号、住所、スタッフ情報の記載がない。ロゴの画像も奇妙だ。
驚くべきことに、このサイトはHON(Health On the Net Foundation*5)コードを取得しており、医師が執筆している。なぜ、このサイトが影響を受けてしまったのだろうか? 受賞歴の記載あり。医師が監修したジャーナリズムあふれる記事。我々について(About us)のページはもっと目立たせるべきだろうか?
問い合わせのための電話番号や住所の記載はない。記事ページには広告が多すぎる。ページ上部のアコーディオン式の広告を煩わしく感じるユーザーは多いだろう。また、ロゴのリンクシステムが非常に奇妙だ。画像のマップは検索エンジンが理解するのは難しいだろう。
*5 信頼のある医療情報であることを証明する非営利機関
我々についてのページの記載内容が不十分で、パブリックサービスの警告文のように読めてしまう。彼らが何者であるかが書かれていない。サイト全体としては正しいことをしている。
HONコードを取得している点は素晴らしい。電話番号と住所の記載はない。お問い合わせページは別のドメイン。ページのフッターには別の名前のリンクがある。
トップページはほぼ無限スクロールのような作り。我々についてのページとお問い合わせページがなく、電話番号と住所などの記載もない。
私がこれらのサイトを確認したのは数週間前であるから、すでに何らかの変更を加えている可能性はある。また、その中で順位が回復したサイトもあるかもしれない。上記で私が言及した項目が、欠落している項目の全てではない。我々についてのページを追加したことで、全ての問題が解決されるわけではないだろう。
過去、また、この記事で私が言及したシグナルは、非常に議論をうむ内容であるだろう。私の意見に反対する者もいるだろう。
しかし、私の意見は、SEOの専門家がランキング要素であると信じていたものと、Googleがそうではないと否定したものとの乖離についての説明に非常に近しいものとなっているはずだ。
Google社員はときおり意味論のゲームに興じると私は考えている。彼らは、議論を生む要素(CTRや感情分析など)は直接のランキング要素ではないと発言する。なぜなら、こうした要素は品質スコアの複雑な評価システムの説明となる場合と、説明とならない場合もあるからだ。
例えば、私の品質スコアに対する推測が実際の仕組みに近しかった場合を考えてみよう。同様のトピックで異なる2つのページが有り、関連性やCTRは高い。
しかし、その他の要素の組み合わせにより、どちらか一方の品質スコアが、もう一方よりも、非常に高くなる可能性もある。別のケースでは、高いCTRによって高品質と判断される場合もあるだろう。
高品質なページのモデル(パターン)は、ダニー・サリバン氏が表現した”検索のレシピ”であるようだ。異なるタイプのページの品質スコアを決定するために、複数の要素が異なる組み合わせと重み付けをされているのである。
サポートベクター回帰やニューラルネットワークを使用することにより、品質スコアのリバースエンジニアをほぼ不可能なものにするだろう。
なぜなら、それらは非常に全体的で包括的なものであるからだ。品質スコアはゲシュタルトである。これが、アルゴリズムの影響を受けてしまったサイトに対し、Googleが「全体的な品質を向上するように努めよう」や「最高品質のコンテンツの作成に注力しよう」のような非常に曖昧なアドバイスを送る理由にもなっている。
技術的なSEOを無視すれば、品質スコアの低いサイトがその順位を改善するために、1つや2つの改善ですむことはほとんどないだろう。グレン・ゲイブ氏がアルゴリズムの更新に影響を受けたサイトを調査した後、次のメッセージを残している。
「サイトオーナーは特定の、単一の要素を注視すべきではない。下降した理由が、たった1つの要素、といったことは絶対にないのだから」
では、品質スコアが非常に複雑で全体的なものであることを理解することが、自身の品質スコアを改善するために、どのように役立つのだろう?
良いお知らせとして、多くのSEOのガイダンスは非常にわかりやすい。技術的に”健全な”SEOを実装し、エラーページやブランクページを極力少なくする。不必要で、内容の薄いコンテンツを削除する。ガイドラインに違反したリンクビルディングは行わない。
SEOは、それ自体が全体的で包括的な取り組みとなっている。自身のサイトを最適化するために正しいと思われる全てのことを行おう。ユーザーがあなたのサイトは最新の状態に保たれていると感じる要素を確認しよう。我々についてのページ、お問い合わせページ、プライバシーや規約、カスタマーサービス、そして、コンテンツ自体を適切なタイミングで更新する。
技術的なSEOの要素に加え、ユーザビリティ、ユーザー体験、カスタマーサービス、コンテンツの品質などをより良いものにする必要がある。
自身のサイトを厳しく査定し、うまくいっていない箇所の特定と、改善を進めよう。ユーザーの目線を持って自身のサイトを評価し、ユーザーのニーズを満たすためのコンテンツを作成しよう。否定的なレビューへも対応し、自身のサイトを好ましく感じてくれたユーザーからのレビューを引き出そう。自身のサービスとクライアントとの軋轢がるのであれば、その軋轢を生む要因を除外し、カスタマーサービスの慣習を改善しよう。
あなたは最高のコンテンツを作成する必要があり、コンテンツ作成には、最高のコンテンツ作成者の獲得が必要となる。
最後に、自身のコミュニティと積極的に関わることで、先進的なレピュテーション・マネジメントに取り組もう。オンラインでもオフラインでも、長い期間、継続的に行うのだ。ソーシャルメディアへのエンゲージを高め、こうしたチャネルでの露出機会を増やす。評判形成のため、専門家としてのアドバイスを、オンラインで無料にて提供しよう。あなたの業界のプロフェッショナルなグループの一員となろう。プロとして振る舞い、オンラインで感情的になることは避けよう。
こうした試みをすることで、品質スコアにとって良いシグナルを発生させることができ、いずれ大きな利益を獲得することになるだろう。
とても複雑なテーマであり、中には議論を呼びそうな主張も含まれていると感じました。どちらが正しいかを証明することはほぼ不可能なことかもしれませんが、どちらが正しいにせよ、行き着く結論は同じようなものになると考えています。
「ユーザーが自身のサイトを安心して利用し、信頼してもらうために何ができるのか?」を、SEOの目的という以前に、サイト運営そのものの施策として常に考えていきたいですね。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。











{kind=link}