![]()

![]()
schema.orgのボキャブラリが導入されたことにより、検索エンジンでのビジビリティを改善するために構造化データを採用する試みのメリットに、現在、大きな注目が集まっている。
このメリットの中で最も広範に取り上げられ、そして、容易に証明することが可能なのは、リッチスニペット – 言及されるリソースのタイプに特化した情報を含む特別にフォーマットされた検索結果のブロック – の生成である。
それでは、構造化データを利用するSEOのメリットは他にはないのだろうか?
グーグルは、構造化データを採用する利点は(構造化マークアップとして)リッチスニペットの生成に限られていると主張しているが、一方で、構造化データの利用自体がウェブページの検索におけるランキングを改善すると大胆に断言する人達がいる。
個人的にはその中間が正しいのだと思う。構造化データの採用はランキングの改善を約束するものではないが、メタデータを提供することで、ウェブリソースの内容を検索エンジンにより深く理解してもらえる可能性はある。
後ほど触れるが、検索エンジンは、ランキングアルゴリズムでリッチスニペットを返す上で信頼に値すると認めた情報を故意に無視しなければならなくなる。不可能ではないが、可能性は少ない(と私は思う)。
検索のビジビリティを上げるために、構造化データが最も幅広く利用されているのは、- 構造化マークアップと言われることが多い – HTMLのアトリビュートを使って、ウェブページ内に埋め込むメカニズムである。
構造化マークアップを用いて、プレゼンテーション層(ウェブページを見る際に表示される層)はデータと分離される(コンピュータが見る層)。
すると、検索エンジンの推測の量が減る。なぜなら、ページの要素に関する明確な情報を手に入れることが出来るためだ。
例えば、10:12は時間のフィールドでマークアップされていれば、比率と誤解される可能性は低い。
現在幅広くサポートされている構造化マークアップの主な種類を挙げていく:
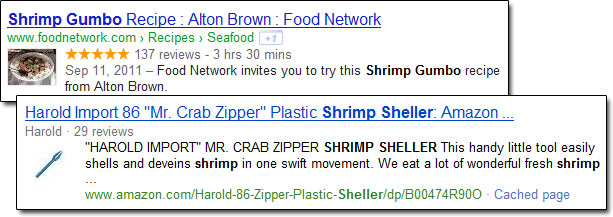
上に挙げたアトリビュートベースのマークアップのフォーマットは、オンラインの製品の提供、レビュー、そして、イベント等、現在サポートされているタイプのリッチスニペットを生成することが全て出来る。
グーグルのレシピのリッチスニペット、下はビングの製品のリッチスニペット
しかし、構造化データは、SERPでのランキングが上がると言う形で、もしくは、通常ならば除外される可能性が高いものの、検索結果へ掲載されると言う形で、検索エンジンのビジビリティを改善する上でも役に立つのだろうか?
グーグルは、“リッチスニペットのためにデータをマークアップしてもページの検索結果でのランキングには影響を与えない”と断言している。
しかし、同じページで次のような情報が提供されている:
「この情報を提供したことろでページ上のコンテンツの見た目には影響を与えないが、グーグルがページを理解し、情報を提示する上で役に立つ。」
構造化マークアップはグーグルの“情報を提示”するプロセスを改善すると言うメリットは、リッチスニペットの生成に向けて利用を促していることからも明白である。
それよりもこの文章において興味深いのは、構造化マークアップが、グーグルがコンテンツを理解する上で役に立っていると言う点である。
コンテンツをよく理解してくれるなら、少なくとも、理解度の向上によって当該のコンテンツを関連するクエリと関連付けるプロセスが改善する場合、コンテンツを検索結果に含めてもらえる、もしくは、ランキングを上げてもらえると考えるのは妥当ではないだろうか?
構造化コンテンツに注釈を付ける取り組みに関するビングの記事にも、同じような見解が垣間見れる(ランキングに限定しているわけではないが):
「データに注釈をつけても表示されるコンテンツは変わらないが、サイトに掲載しているコンテンツのタイプに関する貴重な情報をビングに与えることになる。ビング側は、注釈を良い目的のために利用する。例えば、注釈を使って、検索結果のビジュアル面での魅力を高めたり、ビングのデータのソースを補い、認証したりすることが出来る。」
グーグルのように、ビングも構造化マークアップの価値はリッチスニペットの生成を通り越し(検索結果の“ビジュアル面での魅力”)、通常、注釈が付けられたコンテンツに関する付加的な状況を提供する効果も見込めると示唆している。
繰り返すが、個人的には、コンテンツの理解の改善、または、見たところ優れた構造化注釈の力によってコンテンツが信頼に値すると考慮されることにより、少なくとも、関連するクエリに対して検索結果のランキングが上がる可能性はあるように思えてならない。
この見解には、別のタイプのデータの注釈を紹介した後、比較する意味で再び触れる: それはメタデータが豊富なXMLファイルである。
検索エンジン(特にグーグル)は、XML ファイルの提供を通して直接リソースに関する情報を与える様々なプロトコルを以前から採用している。ここではサイトマップとRSSフィードを例に挙げて考えてみよう。
正確に言うと、このようなデータのタイプは、“構造化データ”ではない。なぜなら、厳密に言うとリソース・ディスクリプション・フレームワーク(RDF)ではないからだ。
しかし、検索エンジンはこのようなXMLフォーマットを理解し、問題なく消化することが出来るため、同じ種類の情報を“正しい”構造化データとして導き出す能力を持っているはずである。つまり、XMLフォーマットのデータは、検索エンジンにURLに関するメタデータを与えるのだ。
構造化マークアップのメリットがSERPでのリッチスニペットの見た目を超えるように、サイトマップおよびRSSのメリットも以前から称賛されているインデックス、そして、購読に関する利点を超えている可能性がある。
XMLのサイトマップは、基本的に検索エジンにドメインで利用可能なURLに関する情報を教え、そして、重要なページ、あるいは頻繁に変更が加えられるページを示唆する。すると、インデックスを再び行ってもらえる可能性が高まる。
しかし、ウェブページ自体では提供されていない可能性のある情報を含む、URLに関するより具体的な情報を検索エンジンに与えることも出来る。
各種のサイトマップ、そして、グーグルによるそれぞれの記述の例として次のタグを考慮してもらいたい。
これらのタグは、インデックスを確実にする、または促進する以上の価値を持つ。検索エンジンに付加的な情報を与え、リソースを関連するクエリの結果に表示してもらえる可能性があるのだ。
SEOに関して言えば、動画、ページ、そして、イメージが提供されているメタデータに基づいて検索結果に表示されると言う効果が期待できる。
そのため、イメージのサイトマップ内で「ダブリン、アイルランド」とタグ付けされたイメージは、この地理的な情報に欠ける別のサイトの同じイメージよりも、「写真 ダブリン」で表示してもらえる可能性は高いだろう。
同様に、証券コードのシンボルを割り当てることで、グーグルがニュースの記事が企業に関連しているかどうかを判断する際に役に立つ。「アップル」が企業を意味しているのか、食べ物を意味しているのかグーグルが判断出来かねているなら、「NASDAQ:AAPL」を加えることで、曖昧さを排除することが出来るだろう。
だからと言って、サイトマップのタグを利用すると、関連するクエリに対して、SERPでのビジビリティが高まると主張しているわけではない。グーグルは、地理的な関連性に対してイメージが表示されるページの背景に大きく依存しており、また、メタデータがなくてもコンピュータメーカーとフルーツの違いはほぼ間違いなく理解することが出来るはずである。
しかし、サイトマップが提供するタイプのデータが、グーグルがリソースの内容を理解する上で役に立っていないとしたら、この情報を積極的にグーグルが求める理由を知りたくなってしまう。
RSS フィードがメタデータを提供して、検索エンジンによって消化され、- そして、利用される点においてはXMLのサイトマップと概念は似ている(RSSを購読メカニズムとしてのみ見なしているウェブマスター達がよく見落としている点である)。
私は以前定期的に読んでいるブログを追跡し、サイトワイドの<title>タグを差別化したことがある。グーグルは <title>タグ自体ではなく、RSSのタイトル<item>を検索スニペットで返していたため、SERPで理由としてこのタグの存在を挙げることが出来なかった。RSSの提供がこのブログのエントリのランキング高める効果があるかどうかについての推測は避けるが、少なくともSERPでのエントリのビジビリティにプラスの影響を与える点は間違いないはずだ。
構造化データを利用すると、検索エンジンにリソースをより深く理解してもらえる。うまく採用してもらうと、構造化データは、検索エンジンは、“へぇ”レベルではなく、なるほど!レベルの納得を引き出すことが出来る。つまり、「確かに製品の価格だけど…それで?」ではなく、製品の価格だね、ハッキリして良かったよ!と言う捉え方をしてもらえるのだ。
検索エンジンにリソースに関する情報をさらに与えることが出来るため(<img> ALT アトリビュート、<h1>に値するタイトル等)、従来のHTMLの最適化が役に立つように、構造化データもまた同じようなメリットが見込める。
グーグルニュースのサイトマップが、企業のアップルとフルーツのアップルをグーグルが区別する上で役に立つように、構造化マークアップもまた曖昧さが問題になっている状況でプラスの効果が望める。
グーグルとビングに対して、歌手のTom Jonesではなく、ページで書籍のTom Jonesを取り上げている点を伝えているなら、後者は「tom jones fielding」のクエリの検索結果で(Fieldingは『Tom Jones』の作者の名前)、そして、「tom jones musician」の検索結果で前者が表示される可能性が高いのは当然ではないだろうか。
そのため、構造化データの利用が、リンクや多くの質の高いコンテンツに期待できるような上位へのランクインに直接結びつかなかったとしても、その他のメタデータを用いることで、プラスの効果が見込める可能性は十分にある。
通常のSEOのスタッフなら、<title>タグを最適化して、重要なキーワードを含め、そして、ページの内容を反映させるだろう。この取り組みによって、ターゲットに選んだ検索の用語に対するビジビリティは確実に改善されるだろうか?そうとは言い切れない。
しかし、検索エンジンに対して、ページに関する情報をさらに提供することは出来る。その情報を検索エンジンはその他のデータ点と比較し、有効な場合は恐らく利用するだろう。だからこそ、<title>タグを用いるウェブページが、このタグを持っていない同様のウェブページよりも通常パフォーマンスが良い傾向が見られるのだ。
この原則は、アンカーテキスト、フラットな情報の構造、そして、ブレッドクラムの最適化等、全ての最適化の手法および戦略に当てはまる。
ただし、このような取り組みは、構造化データのように、グーグルがページおよびサイトのトピックを的確に判断する上で役に立つものの、採用したからと言って“上位へのランクイン”を保証するものではない。
この記事の中で述べられている意見はゲストライターの意見であり、必ずしもサーチ・エンジン・ランドを代表しているわけではない。
この記事は、Search Engine Landに掲載された「Employing Microformats & Structured Data For Enhanced Search Engine Visibility」を翻訳した内容です。
マイクロフォーマットに限らずサイトの構造化が検索エンジンにその内容を正しく伝えるためにも大事、という話でした。かなりのボリュームなので一読して全て理解というわけにはいかなさそうですが、気になる点や実践できることがあれば、自社サイトでもそろそろ意識してみても良い頃かもしれません。 — SEO Japan
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










