![]()

![]()
![]()

「いかにしてWebサイトのE-A-Tを高め、検索エンジン(Google)に認識してもらうか?」は、ここ数年で最も関心の高いトピックと言って良いでしょう。
特にYMYL領域において重要になるE-A-Tですが、今回は構造化データを活用してGoogleのE-A-Tの理解を助けるという内容になります。
適切に実施するにはそれなりの工数がかかるものの、実施すべき価値がある内容となっており、ぜひ参考としていただければと思います。
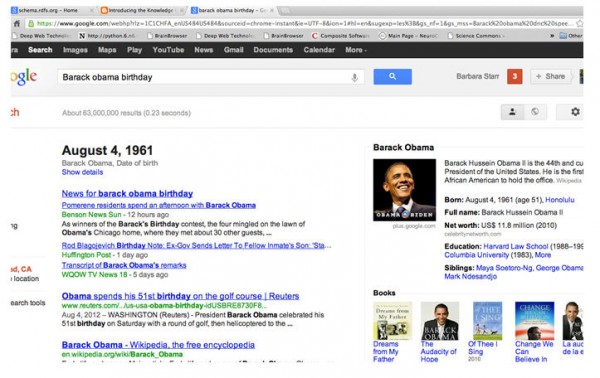
Googleの提唱する概念であるE-A-T(専門性・権威性・信頼性)は、近年のSEO界隈で話題になり、多くの神話や誤解の源となっている。
E-A-Tを取り巻く最も顕著な疑問と怪奇のひとつは、「E-A-TがGoogleのアルゴリズムにおける直接的なランキング要素かどうか」、そしてその程度である。
しかし、Googleは、E-A-Tがアルゴリズム内で果たす役割と、それが「検索品質評価者によってどのように使用されるか」については一貫しており、E-A-T自体が定量化できることとは対照的に、「Googleのアルゴリズムは、ページの権威性及び信頼性に関連するシグナルを識別する」と述べている。
この点について明確にするために、Googleは最近この疑問に対しての回答を更新した。
参考:Google のコア アップデートについてウェブマスターの皆様が知っておくべきこと
この回答では、E-A-T自体は直接のランキング要素ではなく、Googleが優れたコンテンツを評価し、順位付けするために使用する多くのシグナルを含むフレームワークであることが示されている。
2020年3月のアップデートでは、Googleは次のように述べている。
E-A-Tを基準とした観点から自身のコンテンツを評価することは、アルゴリズムがコンテンツの順位付けに使用するシグナルと概念的に一致させるのに役立つ場合がある。
GoogleのE-A-Tに関するメッセージには、解釈と議論の余地が多く残されている。その結果、多くのSEO担当者の間で、ひとつの共通する質問が生じる傾向がある。
「E-A-Tが非常に重要である場合、E-A-Tを改善するためにコンテンツをどのように最適化できるのだろうか?」
E-A-Tに関連する質問に対するGoogle公式の回答では、次に何をすべきかを多くのSEO担当者が悩んでいる。
しかし、E-A-Tだけでなく、全体的な検索パフォーマンスを改善するために使用できる方法が1つある。
それは構造化データ(Schema.org)を最大限活用することである。
目次
構造化データの適切な使用は、いくつかの理由でE-A-Tの改善に役立つ。
まず、構造化データはエンティティ間の関係を確立し、固めるのに有効だ。特にオンラインで言及されているものの関係を確立する上で機能する。
Google独自の言葉で言い換えると、こうだ。
「ページに構造化データを含めて、ページの内容についての明確な判断材料を提供すると、Google でそのページをより正確に理解できるようになります。」
引用:構造化データの仕組みについて
構造化データを利用して、エンティティ間の関係を確立すると、特定のページ・Webサイト、またはエンティティのE-A-Tを評価するGoogleの働きを合理化することができる。
ナレッジグラフとGoogleの特許専門家であるビル・スロースキ氏は、次のように述べている。
構造化データは、検索エンジンが人間の常識を持っていないがために把握できなかったことで必要としている正確さのレベルを補う
検索エンジンがページに含まれているエンティティについて確固たる情報を持ちえない場合、検索エンジンがそれらのエンティティの専門性・権威性・信頼性を正確に評価することは困難な場合がある。
構造化データは、同じ名称を持つエンティティを明確にするためにも役立つ。そして、これはE-A-Tを評価するにあたって間違いなく重要だ。
スロースキ氏は、構造化データがどのように機能するかについて、いくつかの興味深い例を提供してくれた。
ページの主体となる人物がいたとして、その人物が他の誰かと同姓同名だった場合、sameAsプロパティを使用して、Wikipediaなどのナレッジベースでその人物に関するページをマークし、参照する場合に明確にすることができる。
例えば、一般的にマイケルジャクソンは元国土安全保障局長ではなく、Popの王を意味する。彼らはまったく異なる人物だ。
バンドボストンのように、企業は都市や他の人物と共通する名前を持っているケースがある。
構造化データは、基本的にサイトのトピックやトピックに貢献した個人に関するGoogleの重要な情報を補う方法として機能する。
これはGoogleがページを認識するにあたって重要なファーストステップであり、次にサイトとそのコンテンツ作成者の権威性と信頼性を正確に評価できるようになる。
構造化データを実装する方法はいくつかある。
Googleが推奨しているJSON-LD、Microdata、RDFaだ。
Googleは最近、JavaScriptとGoogleタグマネージャーを使用して、動的に構造化データを追加することに関するドキュメントをリリースした(JavaScript を使用して構造化データを生成する)。
WordPressで作られたWebサイトの場合、ポピュラーなSEOプラグインであるYoastには、多くのスキーマ組み込み機能があり、ここ数ヶ月で新しいスキーマタイプと機能を積極的に拡張している。
E-A-Tを改善するために構造化データを実装する方法は、Webサイトでマークアップされたスキーマのタイプほど重要ではない(スキーマタイプ>実装方法)。
E-A-Tを改善するには、Webサイトにコンテンツを提供して会社を構成している著者や専門家の信用、評判、信頼性に関する情報を検索エンジンに提供する必要がある。
またE-A-Tは、ブランドの評判と、ユーザーがWebサイト・製品・サービスを使用する際に体験することを網羅している。
これらの側面は、可能な限りスキーマでマークアップを施すためには特に重要だ。
スキーマを適切に構造化することも重要だ。適切に構造化することで、検索エンジンは、特定のエンティティの様々な属性と、他のエンティティとの関係を理解できる。
アレクシス・サンダース氏が、JSON-LDに関する記事で、スキーマのネストの利点とそれを正しく行う方法に関する素晴らしい説明を提供してくれている(A Guide to JSON-LD for Beginners)。
例えば、以下に示すスキーマは私の個人サイトのトップページからのものであり、正しく行われた場合のネストの様子を示している。
(以下は、Yoastプラグインを使用して、サイト設定を「個人」に設定し、プロフィールのすべての関連フィールドに入力することによって行われたものである)
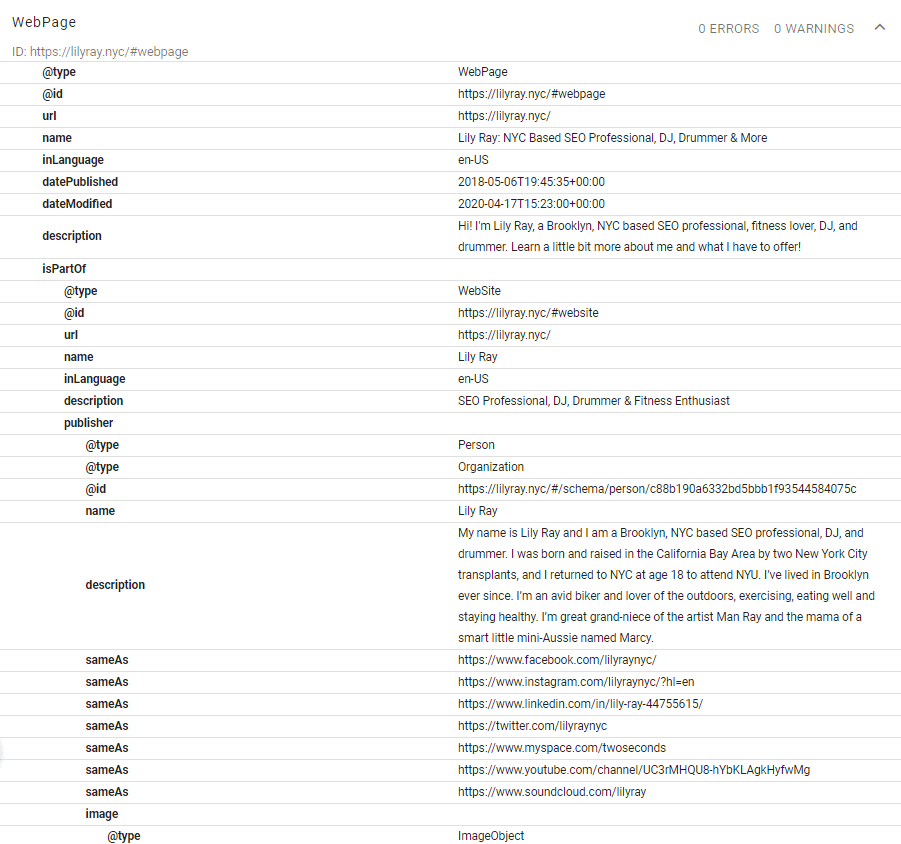
スキーマを適切にネストすることで、次のことが可能になる。
また、ネストにより、同じページに複数の冗長または競合するスキーマタイプが存在するという問題が解消される(多くの場合、複数のプラグインが同時にスキーマを挿入するため)。
例えば、製品ページにおいては、Webサイトの運営者と製品の製造者を明確に区別することが重要だ。
それらを入れ子構造として正しく配置することで、両方が「ページ上に存在すること」だけでなく、役割の違いを明確に説明できる。
組織のE-A-Tについて、検索エンジンに適切なシグナルを送るためには、Webサイトへの提示が重要である様々なスキーマタイプとプロパティがある。
以下は、スキーマを使用して適切なE-A-Tを通知するために最も優先度の高い5つの例だが、これらは多くの要素から成り立っている。
品質評価ガイドラインでGoogleがE-A-Tについて最初に言及したのは、評価者に「専門知識」と「コンテンツ作成者の信頼性」について検討するように求めることだ。
この情報は、人物スキーマを使用して検索エンジンに伝達することができる。
サイト上で創設者・コンテンツ作成者・専門家などの貢献者が記載されている場所に、上記のプロパティを持つ人物スキーマを少なくとも1回含めることを検討してほしい。
(これらの情報がページにも表示されている場合。これは構造化データコンプライアンスの前提条件である)
著者の経歴ページは、このスキーマタイプを掲載するのに適した候補である。
Googleによるガイドライン違反通知を避けるために、スキーマでマークアップされたコンテンツをページに表示する必要があることに注意してほしい(構造化データに関するガイドラインに準拠する)。
人物スキーマの仕様を拡張するもうひとつの方法は、人物スキーマを使用して、Googleのナレッジグラフ上、同姓同名間の人物間における個人の名前を明確にすることだ。
その個人がナレッジグラフに掲載されている場合、sameAsプロパティを使用して、ナレッジグラフのURLにリンクすることを検討してほしい。
(ナレッジグラフに掲載されているかどうかは、Knowledge Graph Searchで確認できる)
適切に構造化データをマークアップすることで、適切な個人のナレッジパネルが特定のクエリに対して確実に表示されるようにするために必要な根拠をGoogleに与えることができる。
ソーシャルプロフィールとして、ふさわしくないsameAsマークアップがあることをGoogleがアナウンスしているにもかかわらず、本来の用途ではない形でsameAsプロパティが使われているケースが存在する。
さらに、Googleに限らず、スキーマを使用する検索エンジンは多いため、sameAsを使用してソーシャルプロフィールを表示することも、おそらく良いアプローチであることを覚えておく価値はある。
組織スキーマは、E-A-T向上の取り組みをサポートするための最良のスキーマタイプのひとつだ。
このスキーマタイプは、会社やブランドに関する追加のコンテキストを追加できる様々なプロパティを提供する。以下に例を示す。
多くの企業は、これらのフィールドや、このスキーマタイプを使用して他の多くのプロパティを活用せずに組織スキーマを実装している。
このすべての情報を組織に関する最も関連性の高いページ(aboutページやコンタクトページ)に組み込み、それに応じてページのマークアップを検討しよう。
著者(Author)スキーマは、ArticleやNewsArticleなど、CreativeWorkまたはReview分類に該当するスキーマタイプに使用できるスキーマプロパティだ。
このプロパティは、コンテンツの一部に対する著者の署名欄のマークアップとして使用する必要がある。
著者プロパティが該当するタイプは、個人または組織のいずれかであるため、サイトが会社に代わってコンテンツを公開する場合は、個人として著者を掲載することが重要だ。
監修者プロパティ(reviewedBy)は、Webサイトの優れたE-A-Tをアピールする絶好の機会だ。
医療や法律記事のレビュアーなど、コンテンツに専門のレビュアーを使用している場合は、コンテンツの正確さを確認した個人として、ページにその名前を表示することを検討しよう。
次に、reviewedByプロパティを利用して、その人(または組織)の名前を一覧表示できる。
これは、作成者がE-A-Tやオンラインでの存在感を欠いている可能性がある一方で、レビュアーがオンラインでの存在感がある真の専門家である場合に使用する優れたアプローチだ。
Yoastを使用しているWordPressのWebサイトのreviewBy機能は、現在ロードマップ内で検討されている。これにより、WordPress内で著者を選択し、コンテンツをレビューした個人を示すことができる。
引用スキーマプロパティ(citation)を使用して、コンテンツが引用またはリンクしている他の出版物、記事、または作品を掲載できる。
これは、信頼できる情報源を参照していることを検索エンジンに示すのに最適な方法だ。これはE-A-T向上における優れた戦略である。
さらに、スキーママークアップに引用を掲載すると、関連付ける他のブランドとの間でブランドを位置付けるのに役立ち、Googleへ信頼性に関する定性的な情報を提供できる可能性がある。
Schema.orgライブラリは、継続的に拡張されている。
また、構造化されたデータ自体は直接のランキング要素ではないが、Googleは一貫して採用しており、検索エンジンがサイトを理解するのに役立つよう、可能な限り多くのデータを使用することを推奨している。
構造化データを通じてコンテンツとサイトに含まれるエンティティをGoogleがよりよく理解できるようにすることで、Webサイトの品質とE-A-Tを評価するための取り組みを合理化し、改善することができるだろう。
進化し続けるSchema.orgライブラリに注意を払い、そこに掲載されている多くのスキーマタイプとプロパティを、コンテンツを構造化する上でのガイドとして採用しよう。
構造化データを活用したE-A-Tのサポート方法について、根拠から具体的な方法までがわかりやすくまとめられた記事でした。
サイトのE-A-Tを担保するためには、その情報をユーザーにわかりやすく提示することも重要ですが、検索エンジンに伝えることも同様に重要です。
現状構造化データは、直接的なランキング要因とはされていないものの、その重要性が今後増していく可能性もあり、可能ならば対応しておきたいところです。
構造化データに関する情報はGoogleからも数多く提供されているため、一度公式ドキュメントを見ておくことを推奨します(https://developers.google.com/search?hl=ja)。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。