![]()

![]()
![]()
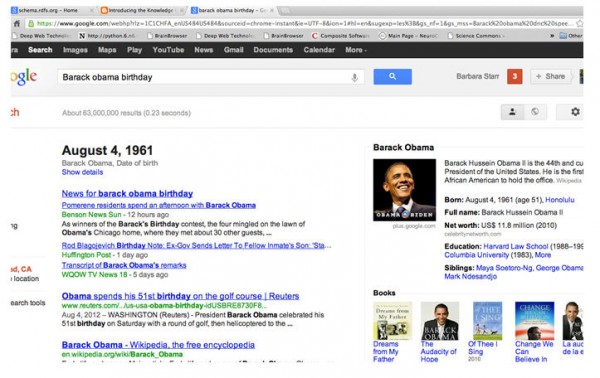
検索エンジンは、ウェブを言葉から、人、場所、そして、物事に変える取り組みを懸命に行っている。今月上旬にアーステクニカに投稿された記事「グーグルとマイクロソフトがウェブを“理解”するため検索エンジンを調教する方法」はウェブの進化を取り上げているが、数年前までしか遡っていないため、この流れを正確にとらえているとは私には思えなかった。
2006年の1月に投稿した「関連するリンクを文書に提供」の中で、私は初めて検索エンジンがウェブページからエンティティを抽出する仕組みを取り上げた。その後、ページからエンティティを特定する方法および抽出する方法が、検索エンジンにとって有益である点を何度も取り上げてきた。これはローカル検索、そして、ユーザーが毎日目にする検索結果の構成に大きな影響を与える可能性のある取り組みにも当てはまる。 SEOmozブログでは、数日前にピート・マイアーズ博士が、ビッグフットアップデート(Dr. ピートが発狂する)を投稿していた。
グーグルが1月に私が「SEOの最重要特許ベスト10 その6 – 検索キーワード中の固有表現を検知」(日本語)の中で説明したアプローチを採用し、改善していたとしたら、Dr.ピートが投稿の中で説明していた“ビッグフット”アップデートのような結果が現れても不思議ではない。
エンティティをあるウェブサイトに関連付け、検索エンジンのユーザーが当該のサイトに関する“サイト検索”を行うことを望んでいると推測するのではなく、グーグルは、エンティティが複数のサイトに関連する可能性があることを認識しているようだ。すると、単一のクエリに対する同じ一連の結果の中で、1つのサイトから3-4つ結果が抽出され、次に再び別のサイトから3-4つの結果が抽出され、場合によってはさらに別のサイトから3-4つの結果が加えられる、私達が時折目にする一連の検索結果が生まれるのだ。
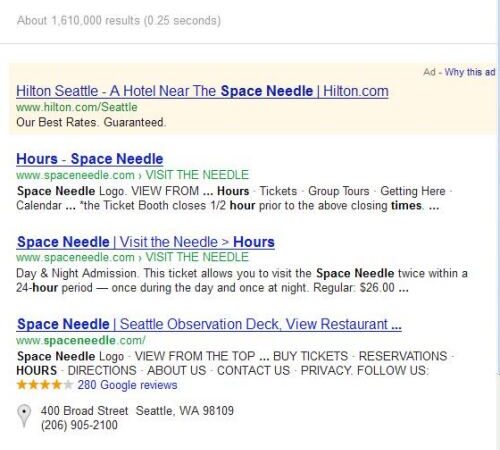
下の例では、[space needle hours]の検索におけるページを提供する1つのサイトの一連の拡大された結果が表示されている。グーグルは、「space needle」(シアトルの中心にそびえるタワー)がエンティティであり、営業時間に関する質問に十分に応えているサイトが存在することを認識していた。しかし、同じようにこのクエリに対して十分な答えを提供しているサイトが他にもあったらどうなるのだろうか?Dr.ピートは、複数の“エンティティの関連”を持つ検索結果に遭遇するようになったと指摘していた。
![A search result for the query [space needle hours] showing 4 results.](https://seojapan.com/wp-content/uploads/2024/02/named-entities-places.jpg)
先週、エンティティの特定および利用を強化する複数の公表済みの特許を私は発見した。ヤフー!の結果はビングによって提供されているが、結果の表示は一部のケースではビングとは異なる。先程紹介したネームドエンティティ(固有表現)の記事では、私は、ヤフー!が、下のジャスティン・ティンバーレイクの検索を行った際の例にあるように、「related movies」や「related songs」や「related people」をサイドバーに表示する可能性があると指摘した:
![On a Yahoo search for [Justin Timberlake], the left column of the search result shows related people such as NSync, Andrew Garfield, Mike Myers, and Joey Fatone, and related movies such as Alpha Dog, and The Love Guru.](https://seojapan.com/wp-content/uploads/2024/02/named-entities-related.jpg)
関連するエンティティの動的な特定
先週公開されたヤフー!の特許には、ヤフー!が時々異なるエンティティをページや記事、もしくは検索エンジンのユーザーのクエリセッションにおいて、短期間で一緒に現れるかどうか等の条件に応じて、関連付ける仕組みが描かれている。
O.J. シンプソンの殺人事件裁判に参加した数名の人々を含む例がこの特許には掲載されている。裁判が行われた際、[o.j.simpson]に対する検索は、シンプソン元被告人に関するページや記事で満たされていた。また、弁護士、裁判官、目撃者、そして、被害者に至るその他の関係者に焦点を絞ったクエリの絞り込みの提案が含まれていた可能性もあった。もしくは、こういったその他のエンティティに関連するページもまた同じ検索結果に含まれていたと推測される。
それではこの出願中の特許のデータを紹介する:
エンティティ間の動的な関係を発見するメソッドおよびシステム
発明: Anish Das Sarma、Alpa Jain、Cong Yu
米国特許申請番号: 20120143875
公開日: 2012年6月7日
申請日: 2010年12月1日
エンティティのフォロー
先週マイクロソフトが公開した特許には、検索エンジンがリアルタイムでエンティティを“フォロー”する決断を下し、エンティティに関する新しい情報がある場合通知を受ける仕組みが描かれている。
これは以前人々が特定のトピックをフォローするため、もしくは特定のトピックをページ内に持つ可能性のあるページを確認するために設定した“アラート”と同じように思えるかもしれないが、実際には異なる。 グーグルニュース等の特定のソースを“購読”するのではなく、このタイプの“エンティティのフォロー”は、専用のクローラーを設定し、特定のエンティティに関連するコンテンツを積極的に探すのだ。それではこの特許のデータを以下に掲載する:
エンティティのフォロー
発明: Zhaowei Jiang、Xavier Legros、Ronald H. Jones JR、Ryan Panchadsaram
付与先: Microsoft
米国特許申請番号: 20120143845
公開日: 2012年6月7日
申請日: 2010年12月1日
概要
この特許は、データソースが制限される問題も解決する完全なエンティティのフォローシステムを説明するものとする。ウェブコンテンツ内のエンティティ関連のオブジェクトを見直す際、ウェブユーザーはリアルタイムでフォローする1つまたは複数のエンティティを指定する。
具体的に言うと、この発明はウェブブラウザ内でのオブジェクトの“フォロー”の選択における動的なクローラーの戦略的な開発を介して管理され、ウェブユーザーが自動的にエンティティをフォロー対象に指定し、当該の指定されたエンティティの新しい情報が投稿された際に、既定の間隔に基づき警告を受ける。
本発明のウェブエンティティエンジンは、流行のエンティティを発見し、その一方で当該のエンティティに対するアウトプットアクティビティ(シグナル等)のストリームを生成する。
エンティティを抽出する難しさ
先週マイクロソフトが発表した特許の一つは、エンティティの特定およびインデックスにおける検索エンジンの内部の仕組みを描写している。 例えば、検索エンジンが「Star Trek」がエンティティであると認識し、情報を集めることを望んでいると仮定しよう。その場合、検索エンジンは、スタートレックのTVシリーズ、スタートレックのTVゲーム、スタートレックの映画、スタートレックのコミックブック等の存在を発見する可能性がある。これらのエンティティは関連していると考えられるものの、実際には別個のエンティティである。
こういった異なるエンティティを区別し、有益になるように整理することが出来る方法が幾つか存在する。例えば、ウィキペディア等のナレッジベースを参考にする可能性がある。ウィキペディアには、スタートレックを分かりやすく紹介するページがあり、2つの異なるテレビシリーズ、3つの映画または映画シリーズ、そして、その他の“関連する”トピックが記載されている。
その他のアイテムも注目される可能性がある。例えば、最初のスタートレックのテレビシリーズは(アニメ版とは異なり)大勢の俳優、監督、そして、その他の関係者が関わっている。検索エンジンは、最初のテレビシリーズで誰がどのキャラクターを演じたのか等を語るドキュメントをウェブ上で探し、当該のページのコンテンツ(およびファクト)を最初のTVシリーズに関連するバージョンのスタートレックのエンティティに関連付けると推測される。
ビングがエンティティの情報を探し出し、抽出し、そして、適切なエンティティと関連していることを確かめるために用いるアプローチに興味があるなら、ビングが利用する可能性のあるその他のアプローチが記載された次の特許にも注目してもらいたい:
発明: Amir J. Padovitz、Bala Meenakshi Nagarajan
付与先: Microsoft
米国特許番号: 20120143869
公開日: 2012年6月7日
申請日: 2012年2月10日
概要
ネームドエンティティの入力を受信し、一連の文書から抽出されるネームドエンティティの入力に対するターゲットのセンスが特定される。ネームドエンティティの入力、ターゲットのセンス、そして、一連の文書に応じて抽出の複雑度の特性が生成される。抽出の複雑度の特性は、一連の文書においてネームドエンティティの入力をターゲットのセンスに対して特定する難しさまたは複雑さを示唆する。
エンティティを使った質問への回答
エンティティに対して検索エンジンが利用する可能性のあるアプローチとして、ウェブをクロールし、特定の人物、場所、または物事に関するファクトおよび情報を集めるアプローチがある。グーグルは「ベーブ・ルースの生年月日は?」(1895年2月6日)や「富士山の標高は?」(1万2388フィート 3776メートル)等の質問には数年前から答えている。
マイクロソフトの特許は、誰かが「XXXXは何年に生まれた?」や「シェイクスピアの作品のタイトルは?」等の質問を尋ねていることに気づいた場合、検索エンジンは、答えを含む可能性のある一連の検索結果を提供するのではなく、答え(または一連の答え)を提供する可能性があると示唆している。それでは、この特許のデータを以下に掲載する:
答えの対象を拡大するためのクエリパターンの生成
発明: Franco Salvetti、Ying Tu、David D. Ahn
付与先: Microsoft
米国特許番号: 20120143895
公開日: 2012年6月7日
申請日: 2010年12月2日
概要
対応する文書の補足として、クエリに対してユーザーに答えが提供される。エンティティおよびアトリビュートの組み合わせに対するクエリのフォーマットが特定される。クエリのフォーマットは、対応するアトリビュートの値を持ち、クエリの答えのリストを形成するエンティティおよびアトリビュートの組み合わせに置き換えられる可能性がある。
エンティティに対するローカル検索および推薦
恐らく、検索ボックスでピザを検索した際に、近郊のピザレストランの場所が表示されたことが何度もあるはずである。しかし、この検索を行い、私達が期待していなかったその他のタイプの情報を考慮していたらどうだろうか?例えば、夜になると急激に客が増えるピザレストランがあるかもしれない。自分の場所から近郊のピザレストランへの交通量の推定によって、通常は最も早く着くピザレストランが、途中で発生した事故の影響によって、1番に表示するのが最善ではなくなるケースも考えられる。
この特許は、この点について次のように説明している:
ロケーションに関連するエンティティを格付けする手法は、例えば、地域の店、レストラン、娯楽施設、イベント等のロケーション関連のエンティティのランクを決める上で用いられる。そのため、一実施形態では、この手法がモバイル検索のログ(モバイルコンピューティングデバイスで実施された検索のログ)を活用し、リアルタイムもしくはリアルタイムに近い早さでロケーションに関連するエンティティの格付けを行う。
ユーザーがクエリを投稿する度に、このメソッドは、検索結果内にその他のユーザーが同じまたは同様のクエリを投稿した後に選択したロケーションに関連するエンティティを調査する。別の一実施形態では、この手法は特定の期間内に対応しているモバイル検索のログのみを掲載する。また、ロケーション関連のエンティティの格付け手法の一実施形態では、検索クエリに対するロケーション関連のエンティティの検索において、リアルタイム検索、そして、ほぼリアイルタイムの検索の2つの選択肢が用意されている。
それではこの特許のデータを以下に掲載する:
発明: Dimitrios Lymperopoulos、Jie Liu、Melissa Wood Dunn、Ashwini K. Varma、Fang Wang、Jen-Hsien Kenny Chien
付与先: Microsoft
米国特許番号: 20120143859
発表日: 2012年6月7日
申請日: 2010年12月1日
先週、ビングは必要に応じてブリタニカ・オンライン・エンサクロペディア・アンサーズを検索結果に表示すると発表していた。ウィキペディアやフリーベースやその他のデータソースを経由するグーグルの「ナレッジベース」のような、この手の「ナレッジベース」の結果は、ユーザーが持っている疑問に対する答えを与え、また、あるトピックを調査しているユーザーがさらに調査を続け、検索をさらに行うきっかけを与える可能性がある。
しかし、双方のエンティティベースの結果以外にも、検索エンジンによるエンティティの特定および関連付けのインパクトは存在する。
今回リストアップした特許は全て先週公表されたものであり、動的なイベントを基に特定のエンティティが関連していることを検索エンジンが特定する仕組みから、エンティティが抽出され、別のエンティティと区別される仕組み等、ネームドエンティティに関連する様々なアプローチを紹介している。また、別の特許では、特定の人物や場所や物事のほぼリアルタイムの追跡を可能にするメソッドが描かれていた。
最後に紹介した特許は、ローカル検索結果で会社をエンティティとして描写し、また、現実世界の判断(とパーソナライゼーション)を基にリアルタイムの結果の中でこういったエンティティを格付けする仕組みを取り上げている。
約一ヶ月前、私は知識は全てGoogleのもの(日本語)を綴り、グーグルによるナレッジベースおよびエンティティの取り組みの一部を紹介した。
この取り組みを行っているのはグーグルだけではなく、この投稿で取り上げた特許はヤフー!とビングが作成したものであり、ウェブの知識を活かそうとする姿勢が窺える。
この記事は、SEO by the Seaに掲載された「Search Engines and Entities」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。