![]()

![]()

多くのSEOコンサルタント、そして、SEO業者が、テクノロジーを用いて自動的にSEOを実行したいと願っている。検索エンジンもまたやはり同じような考えを持っているようだ。Yandex(ヤンデックス)のCTO、Ilya Segalovich氏は、モスクワのヤンデックス社を私が訪問した際、検索エンジンの構築が容易になり、開発者達が容易に利用できる“オープンソース”スタイルのソフトウェアを主に用いたテクノロジーの登場により、グーグルとヤンデックスの競争が発生する可能性が高いのではないかと述べていた。
このように“商品化”される可能性があるテクノロジーには、クローラー、インデックス、さらには、機械学習アルゴリズムも含まれる。Segalovich氏は、「良質な検索エンジンを作るのに2000人ものエンジニアは必要ないのです。その結果、検索エンジンを構成する要素が利用可能になり、素早くアクセスすることが出来るようになるため、いずれ検索を巡る競争は激化するでしょう。」と語った。
目次
ヤンデックスは、大幅に機械学習システムを採用しており、このアプローチを支える2名、アンドレイ・グリン氏とアンドレイ・プラコフ氏と話しをする機会を私は得た。
アンドレイと言う名前ではないと、ヤンデックスでは重役のポジションに就くことは出来ないようだ。アンドレイともう一人のアンドレイは、同社のシステムの仕組みを説明してくれた。その際、アンドレイ・グリン氏は、「SEO業者に上位にランクインするこつを訊かれるのは意外としか言いようがありません。そもそも、私も分からないのです。」と茶目っけたっぷりに語っていた。グリン氏の言葉の意図は後ほど明らかになる。
Andrey Gulin 情報源:Yandex Moscow

Andrey Plakhov 情報源: Yandex Moscow
アルゴリズムを作成する基本的な方法が2つある。手作業、または設定したターゲットに基づきコンピュータに開発させる方法だ。ここまでは単純な話である。もう少し詳しく見ていく必要があるだろう。
そもそもアルゴリズムとは何なのだろうか?ウィキペディアは「アルゴリズムとは、関数を計算するために巧みに策定された指示書の限りあるリストと表現される効果的なメソッド」と定義している。やはり単純だ – 単なるリストである。
それでは、私達自身が検索エンジンだと仮定し、「search marketing company」のキーワードのクエリに応対するプロセスを解明していこう。
まずはじめに既に持っている – または今後収集することが可能な – 様々な形式のデータを集めて、サイトの違いを特定する。
そして、ページのタイトル、メタデスクリプション、コンテンツの本文、またはサイトに向かうリンク内のキーワードの有無を確認するだろう。次のようなリストを手に入れる可能性がある:
次に以下のようにコーパスで全てのページに得点をつけていく:
この通り、検索エンジンを運営するのは非常に簡単である。満面の笑みのユーザーが来るのをくつろいで、ダイヤルをいじって待てばいいのだ。ユーザーは奇妙な生物である。ユーザーは様々な事柄について検索を行うため、検索エンジンの苦労は増える一方であり – しかも本当は何を求めているのかに関する手掛かりをなかなか与えてくれない。
そのため、最大限の関連性を達成するためにアルゴリズムを調整する上で、「search marketing company」に関して行動を起こす際に、「Search Marketing Company」と言う名の会社をユーザーが探している場合、ナビゲーショナルなクエリに対して結果を変更することになるのだが、これが難しい。
サーチエンジンランドの仲間のライター、シャリ・サロー氏は、「ナビゲーショナル」、「インフォメーショナル」、または「コマーシャル」等、複数の重要なクエリのカテゴリについて定期的に説明している。「分類子」を用いて、クエリの異なるタイプを識別することが出来る。問題は、カテゴリーは3つだけではない点であり、数千もの分類子を使う必要性に迫られることになる可能性もある。
検索エンジンのエンジニア達が指摘しているように、毎日、今まで見たことがないクエリが数多く登場する – ジレンマを抱えることになる。少なくとも2つのレベルのアルゴリズムが必要になるだろう: 一つはクエリを識別して、正しいアルゴリズムに導くアルゴリズムであり、そして、もう1つはクエリ応答用のアルゴリズムである。
大勢の検索エンジニアを雇って、各種のアルゴリズムの調整してもらったり、クエリを識別してもらうことも、あるいは、代わりにこの作業を行ってくれるソフトウェアを考案する手もある。なるほど。これこそがヤンデックスが過去18ヶ月間にわたって行ってきた取り組みである。
まず、ヤンデックスは、「マトリックスネット」と呼ばれる“機械学習アルゴリズム”を立ち上げ、その後、ユーザーの意図を理解しようと試みる点に専念する「スペクトラム」を導入した。「スペクトラム」はクエリの分類レベルで動き、マトリックスネットは青のクエリランキングレベルで活動すると言うことも出来るだろう。
2人のアンドレイの話に戻ろう。両氏はこの“機械学習”システムの仕組みを説明してくれた。アンドレイ・グリン氏は「ヤンデックスには検索の質を見極める係がいます。彼らのことを評価者と呼んでいます。評価者は、結果のサンプルに注目し、異なるランキングの要素を与えるシグナルで異なるクエリを評価します。」と述べた。ここで評価者が人間かどうか気になる人もいるので言っておこう。その通り、評価者は人間が務める。
評価者は効果的に良質のサイトの特徴を特定し、これがアルゴリズムが達成するターゲットとなる。その後、既知の利用可能なシグナルを用いて、受信するクエリに対するランキングの公式を判断する手法を考案して、評価者によって決められた質のターゲットを達成するべく努力する。
これは人間が格付けする場合と何が異なるのだろうか?まず公式が状況に応じて変わる可能性がある点が異なる。
多くのSEO業者が、特定の用語においてリンクの本数が多いと上位にランクインする点を発見したと仮定しよう。上位にランクインした新しいサイトが質の評価者が当初設定した仕様書に合わない場合、マトリックスネットが調整を行い、評価者が望んだタイプのサイトを提供する段階に戻す。
同様に質が高いコンテンツを提供する複数のサイトが立ち上げられたものの、利用中の公式とは必ずしも一致しない場合、マトリックスネットは計算を調節し、新しいサイトを公式に反映させる。
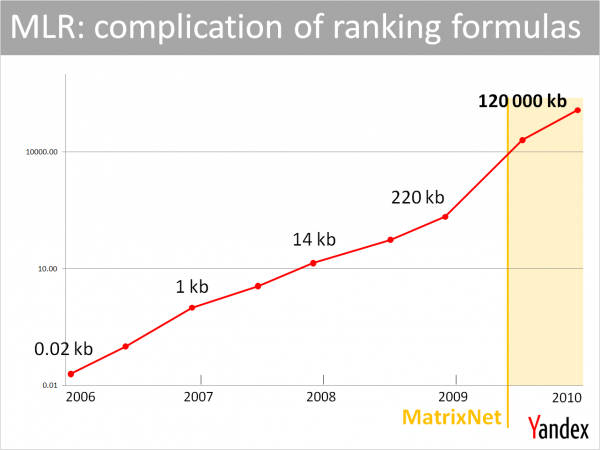
しかし、この手法にはランキングの公式が複雑化してしまう副作用がある。以下のグラフは、一定期間の複雑さの変化を表している – やはりヤンデックスは複雑な公式に対処するテクノロジーの開発が必要になっている点に気づいていた。機械学習アルゴリズム自体、新しい情報が評価者から寄せられ、含む可能性のある新しいシグナルが増えるため、数ヶ月に1度“トレーニングをやり直す”必要がある。
一方、2人のアンドレイとの議論は、サイトを上位にラインクインさせるための有料リンクやクリックスルーの利用に関する問題に差し掛かった。両氏はヤンデックスが有料リンクを特定するためのメソッドを複数用意していることを認めた – 結果に歪みを与える可能性があるため、この点は重要である – どうやらロシアにはヤンデックスが対応しなければならない有料リンクの交換システムが幾つか存在するようだ。また、両氏は、ときおり有料リンクがアルゴリズムに導入され、結果に影響を与えてしまうことがある点を認めた(グーグルがなかなか認めたがらない点である) – しかし、この類のリンクは非常に質の高いサイトのみに存在するようだ。
さらに、2人のアンドレイは、クリックストリームのデータ – 結果ページからサイトへのクリックスルーのデータ – をランキングの“公式”の一部として利用していることを堂々と明かした。
そこで私は避けられない質問を投げかけた。つまり、高いクリックスルー率は、サイトを探す上で良質な要素なのだろうか?どうやら時にマイナスの影響を与えることもあるようだ。アンドレイ・プラコフ氏は、「クリック数はサイトの質の高さを示すために用いられるだけではありません。クリックスルーが高いことが、悪い特徴を示すこともあるのです – 例えばポルノのサイトはこの特徴を持っています。」と語ってくれた。
グーグルもクリックスルーを使っていると思うか両氏に尋ねてみた(一部のSEOのエキスパートは以前からこの点を主張していたが、グーグルが認めたと言う情報は聞いたことがない)。グリン氏は、「経験上、ユーザーの行動に関する情報を利用することなく、競争力の強い検索エンジンを作ることは出来ないと思います。ユーザーの行動のデータ抜きでは良質なランキングを行えない点を私達は経験しています。また、グーグルのランキングは良質なので、グーグルもクリックスルーを利用しているのではないでしょうか。」と述べた。
グリン氏の見解は、SEOの将来にとってどんな意味を持つのだろうか?検索の評価者が、上位にランクインするべきサイト、そして、するべきではないサイトの決定に関して大きな影響力を持っているなら – 私達のシステムは評価者を真似する必要があるかもしれない。なぜなら、上位にランクインする願望は、機械学習アルゴリズムが調整しようと試みる評価者の気持ちに左右されるためだ。また、これこそが、2人のアンドレイがSEO業者に上位にランクインするコツを教えることが出来ない理由でもある。
ヤンデックスで上位にランクインする方法に関するオンラインの情報の多くは、機械学習システムが登場する以前のものである。今後は、上位にサイトをランクインさせるためには、良質なサイトの条件を評価するフォーカスグループを編成する必要があるのだろうか?少なくてもSEOの考えを若干リニューアル必要がある点は間違いないだろう。
この記事の中で述べられている意見はゲストライターの意見であり、必ずしもサーチ・エンジン・ランドを代表しているわけではない。
この記事は、Search Engine Landに掲載された「Automatic Algorithms Are Fundamentally Changing The Shape of SEO」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。









